The clustering factor is a number which represent the degree to which data is randomly distributed in a table.
In simple terms it is the number of “block switches” while reading a table using an index.
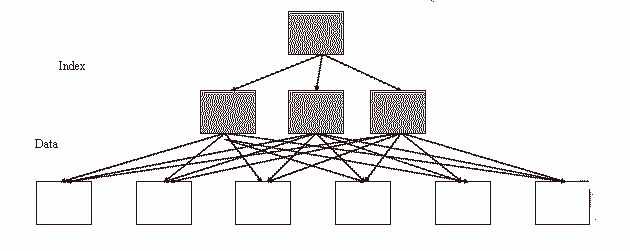
Figure: Bad clustering factor
The above diagram explains that how scatter the rows of the table are. The first index entry (from left of index) points to the first data block and second index entry points to second data block. So while making index range scan or full index scan, optimizer have to switch between blocks and have to revisit the same block more than once because rows are scatter. So the number of times optimizer will make these switches is actually termed as “Clustering factor”.
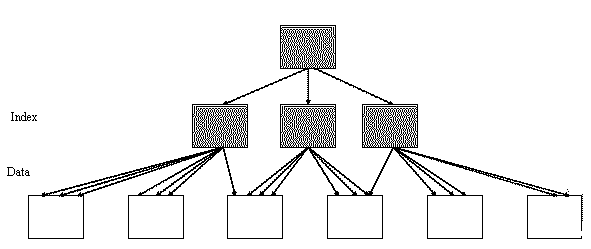
Figure: Good clustering factor
The above image represents "Good CF”. In an event of index range scan, optimizer will not have to jump to next data block as most of the index entries points to same data block. This helps significantly in reducing the cost of your SELECT statements.
Clustering factor is stored in data dictionary and can be viewed from dba_indexes (or user_indexes)
SQL> create table sac as select * from all_objects;
Table created.
SQL> create index obj_id_indx on sac(object_id);
Index created.
SQL> select clustering_factor from user_indexes where index_name='OBJ_ID_INDX';
CLUSTERING_FACTOR
-----------------
545
SQL> select count(*) from sac;
COUNT(*)
----------
38956
SQL> select blocks from user_segments where segment_name='OBJ_ID_INDX';
BLOCKS
----------
96
The above example shows that index has to jump 545 times to give you the full data had you performed full table scan using the index.
Note:
- A good CF is equal (or near) to the values of number of blocks of table.
- A bad CF is equal (or near) to the number of rows of table.
Myth:
- Rebuilding of index can improve the CF.
Then how to improve the CF?
- To improve the CF, it’s the table that must be rebuilt (and reordered).
- If table has multiple indexes, careful consideration needs to be given by which index to order table.
Important point: The above is my interpretation of the subject after reading the book on Optimizer of Jonathan Lewis.
18 comments:
Very Nice way of Explaining Clustering factor.
Explained in simple words...Thanks.
Thanks for explaining in a crystal clear way
Good and simple explanation.
Thank you
- Kumar
Hi,
What if the table has more than one index? Wich way should the table has to be re ordered? (wich column).
Thanks.
Thanks for your visit!
It is relative call. One needs to know the cols that are indexed with their respective usability. It may not happen that rebuilding/reordering table for one index may really hamper CF for another index. But if it happens, one needs to take a call on possible solutions depending upon how much each column is used in sql statements, their impact etc.
very nice article to understand CF..
Thanks a lot.
--Ashwin
ery good article with simple word.Now I am able to gather clear idea about CF
Really good explanation..Thnks a lot.. !! n keep blogging..
Good explanation. Keep it up. Thank you.
Sachin....your explanation is clear and easy to understand. thanks for the info.
-Sai
Great Article.... keep it up,,,
Good Job Sachin!! Very Helpful
Very nice and simple explaination...
Nice blogs from you Sachin...
Good one
Superb explanation with simple words helped me understand it very well. Eventually this was the third time I tried to read and understood it at first attempt.
Very Good explanation
Thank you
Anoosha
Post a Comment