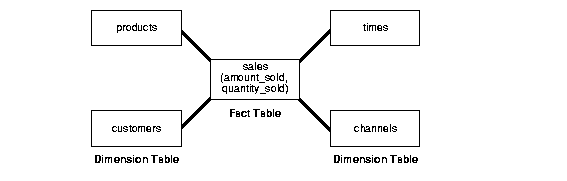
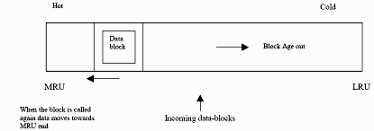
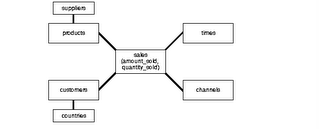
Star SchemasThe star schema is the simplest data warehouse schema. It is called a star schema because the diagram resembles a star, with points radiating from a center. The center of the star consists of one or more fact tables and the points of the star are the dimension tables, as shown in figure.
 Fact Tables
Fact TablesA fact table typically has two types of columns: those that contain numeric facts (often called measurements), and those that are foreign keys to dimension tables. A fact table contains either detail-level facts or facts that have been aggregated.
Dimension Tables
A dimension is a structure, often composed of one or more hierarchies, that categorizes data. Dimensional attributes help to describe the dimensional value. They are normally descriptive, textual values.
Dimension tables are generally small in size as compared to fact table.
-To take an example and understand, assume this schema to be of a retail-chain (like wal-mart or carrefour).
Fact will be revenue (money). Now how do you want to see data is called a dimension.

In above figure, you can see the fact is revenue and there are many dimensions to see the same data. You may want to look at revenue based on time (what was the revenue last quarter?), or you may want to look at revenue based on a certain product (what was the revenue for chocolates?) and so on.
In all these cases, the fact is same, however dimension changes as per the requirement.
Note: In an ideal Star schema, all the hierarchies of a dimension are handled within a single table.
Star QueryA star query is a join between a fact table and a number of dimension tables. Each dimension table is joined to the fact table using a primary key to foreign key join, but the dimension tables are not joined to each other. The cost-based optimizer recognizes star queries and generates efficient execution plans for them.
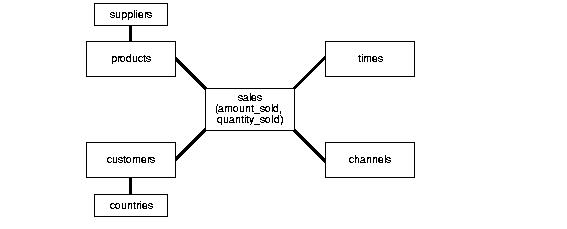
Snoflake SchemaThe snowflake schema is a variation of the star schema used in a data warehouse.
The snowflake schema (sometimes callled snowflake join schema) is a more complex schema than the star schema because the tables which describe the dimensions are normalized.
 Flips of "snowflaking"
Flips of "snowflaking"- In a data warehouse, the fact table in which data values (and its associated indexes) are stored, is typically responsible for 90% or more of the storage requirements, so the benefit here is normally insignificant.
- Normalization of the dimension tables ("snowflaking") can impair the performance of a data warehouse. Whereas conventional databases can be tuned to match the regular pattern of usage, such patterns rarely exist in a data warehouse. Snowflaking will increase the time taken to perform a query, and the design goals of many data warehouse projects is to minimize these response times.
Benefits of "snowflaking"
- If a dimension is very sparse (i.e. most of the possible values for the dimension have no data) and/or a dimension has a very long list of attributes which may be used in a query, the dimension table may occupy a significant proportion of the database and snowflaking may be appropriate.
- A multidimensional view is sometimes added to an existing transactional database to aid reporting. In this case, the tables which describe the dimensions will already exist and will typically be normalised. A snowflake schema will hence be easier to implement.
- A snowflake schema can sometimes reflect the way in which users think about data. Users may prefer to generate queries using a star schema in some cases, although this may or may not be reflected in the underlying organisation of the database.
- Some users may wish to submit queries to the database which, using conventional multidimensional reporting tools, cannot be expressed within a simple star schema. This is particularly common in data mining of customer databases, where a common requirement is to locate common factors between customers who bought products meeting complex criteria. Some snowflaking would typically be required to permit simple query tools such as Cognos Powerplay to form such a query, especially if provision for these forms of query weren't anticpated when the data warehouse was first designed.
In practice, many data warehouses will normalize some dimensions and not others, and hence use a combination of snowflake and classic star schema.
Source: Oracle documentation, wikipedia